Microsoft Unveils Harrier-OSS-v1: New Multilingual Models Released
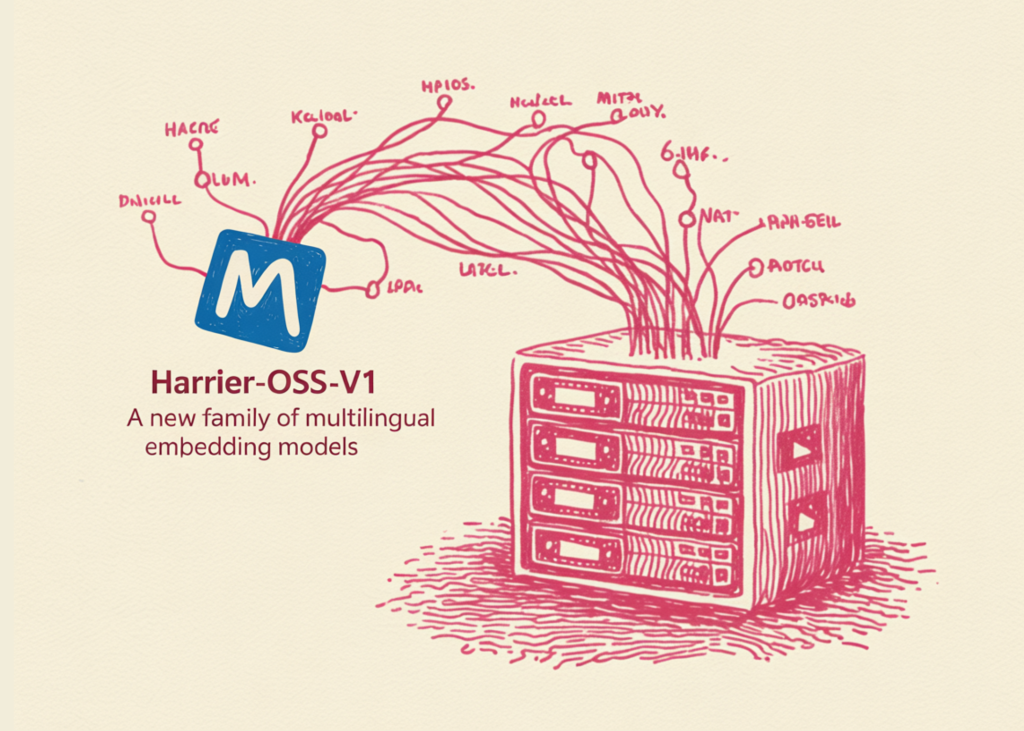
Microsoft has announced the release of Harrier-OSS-v1, a family of three multilingual text embedding models designed to provide high-quality semantic representations across a wide range of languages. The release includes three distinct scales: a 270M parameter model, a 0.6B model, and a 27B model. The Harrier-OSS-v1 models achieved state-of-the-art (SOTA) results on the Multilingual MTEB (Massive Text Embedding Benchmark) v2.
For AI professionals, this release marks a significant milestone in open-source retrieval technology, offering a scalable range of models that leverage modern LLM architectures for embedding tasks. The Harrier-OSS-v1 family moves away from traditional bidirectional encoder architectures like BERT that have dominated the embedding landscape for years. Instead, these models utilize decoder-only architectures, similar to those found in modern Large Language Models (LLMs).
The use of decoder-only foundations represents a shift in how context is processed. In a causal (decoder-only) model, each token can only attend to the tokens that come before it. To derive a single vector representing the entire input, Harrier utilizes last-token pooling. This means the hidden state of the very last token in the sequence is used as the aggregate representation of the text, which is then subjected to L2 normalization to ensure the vector has a consistent magnitude.
The Harrier-OSS-v1 models are characterized by their varying embedding dimensions and their consistent support for long-context inputs. The 32,768 (32k) token context window across all three sizes is a significant feature for Retrieval-Augmented Generation (RAG) systems. Most traditional embedding models are limited to 512 or 1,024 tokens. The expanded window allows AI developers to embed significantly larger documents or code files without the need for aggressive chunking, which often results in a loss of semantic coherence.
One of the most important operational details for AI developers is that Harrier-OSS-v1 is an instruction-tuned embedding family. To achieve the benchmarked performance, the model requires task-specific instructions to be provided at the time of the query. This instruction-based approach allows the model to adjust its vector space dynamically based on the task, improving retrieval accuracy across different domains such as web search or bitext mining.
The development of the Harrier-OSS-v1 family involved a multi-stage training process. While the 27B model provides the highest parameter count and dimensionality, the Microsoft team utilized specialized techniques to boost the performance of the smaller variants. The 270M and 0.6B models were additionally trained using knowledge distillation from larger embedding models, allowing them to achieve higher embedding quality than would typically be expected from their parameter counts.
The Multilingual MTEB v2 is a comprehensive benchmark that evaluates models across diverse tasks, including classification, clustering, pair classification, and retrieval. By achieving SOTA results on this benchmark at release, the Harrier family demonstrates a high level of proficiency in cross-lingual retrieval, particularly valuable for global applications where a system may need to process queries and documents in different languages within the same vector space.
Похожие статьи

Announcing Key AI News from February
Google unveiled key AI updates, including new tools and partnerships at the AI Impact Summit in India.
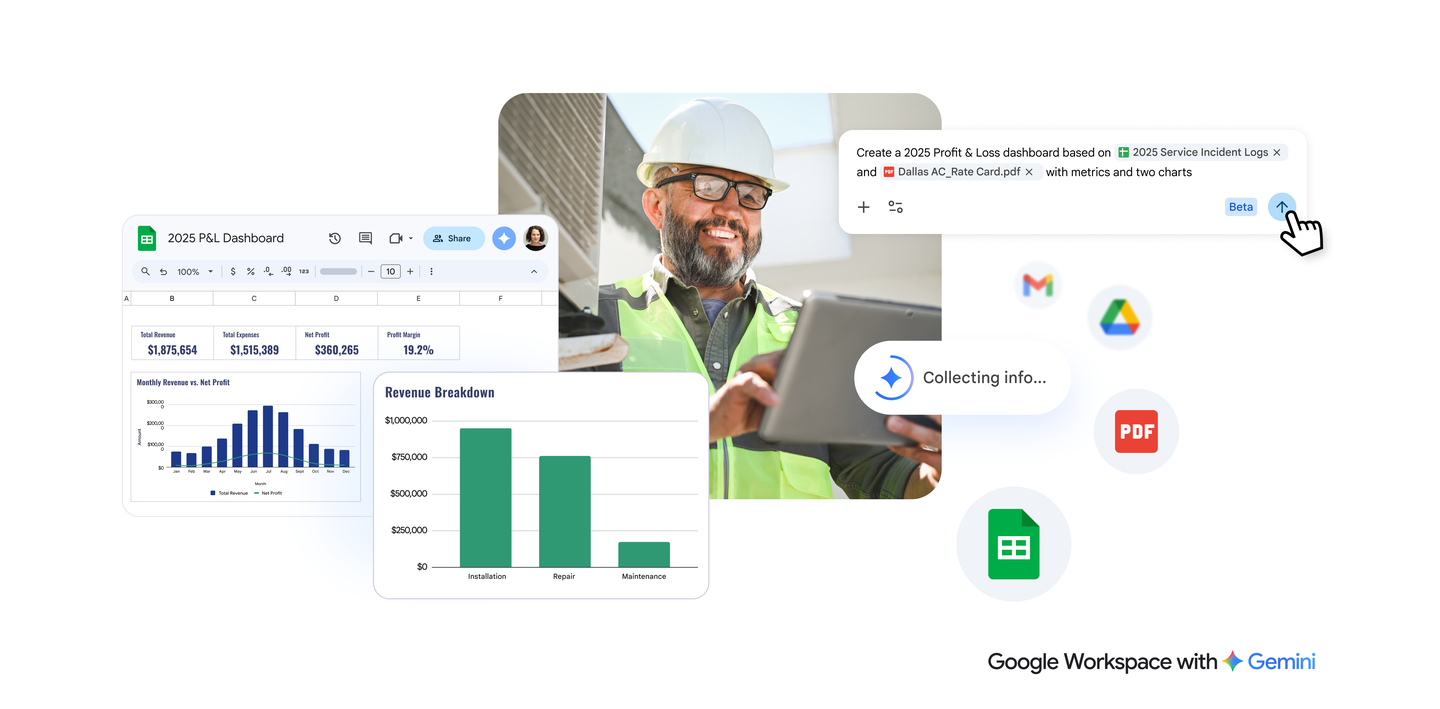
Gemini in Google Sheets Achieves State-of-the-Art Performance
Gemini in Google Sheets has achieved remarkable results in spreadsheet editing.
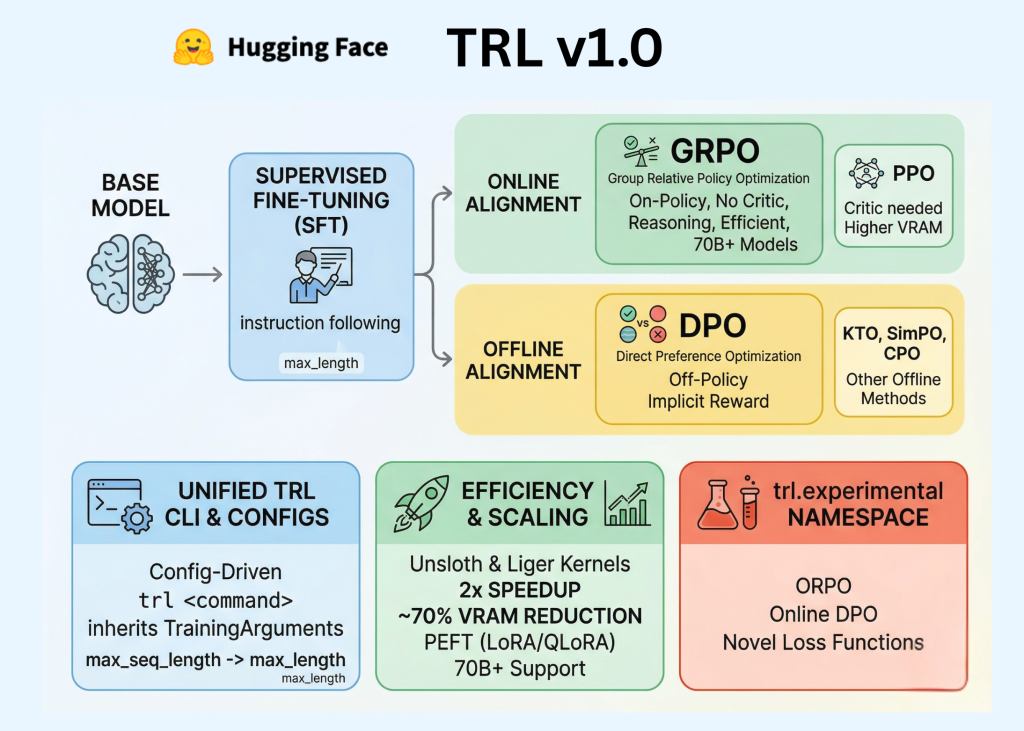
Hugging Face Launches TRL v1.0: A Unified Post-Training Stack
Hugging Face has launched TRL v1.0, setting a new standard in LLM post-training.