Представляем DSGym: новый фреймворк для оценки агентов в Data Science

Современные бенчмарки в области Data Science сталкиваются с проблемами несовместимости интерфейсов оценки. Многие задачи можно решить без использования исходных данных, что создает дополнительные сложности. Мы представляем DSGym — интегрированный фреймворк для оценки и обучения агентов Data Science в замкнутых средах выполнения. С помощью DSGym мы обучили современный открытый агент Data Science.
Data Science является основным двигателем современных научных открытий. Однако оценка и обучение агентов Data Science, основанных на языковых моделях, остается сложной задачей, так как существующие бенчмарки оценивают изолированные навыки в разнородных средах выполнения, что затрудняет интеграцию и честные сравнения. DSGym предлагает единую платформу, которая объединяет различные наборы для оценки Data Science за единым API с стандартизированными абстракциями для наборов данных, агентов и метрик.
DSGym не только унифицирует и уточняет существующие бенчмарки, но и расширяет их за счет новых научных задач анализа (90 задач биоинформатики из академической литературы) и сложных соревнований по моделированию (92 соревнования Kaggle). Кроме того, DSGym предоставляет генерацию траекторий и синтетические конвейеры запросов для обучения агентов, что мы продемонстрировали, обучив модель с 4 миллиардами параметров на 2000 сгенерированных примерах, достигнув передового уровня производительности среди открытых моделей.
Одним из основных вкладов DSGym является абстракция сложности выполнения кода за контейнерами, которые могут выделяться в реальном времени для безопасного выполнения кода. Эти контейнеры поставляются с предустановленными зависимостями и доступными для обработки данными. DSGym предлагает единый интерфейс JSON для всех бенчмарков, где каждая задача представлена в виде: файлов данных, запроса, метрики оценки и метаданных. Наша цель — сделать дизайн модульным и простым, чтобы добавление новых задач, каркасов агентов, инструментов и скриптов оценки было проще для пользователей.
Задачи в DSGym разбиты на две основные категории: Анализ данных (ответы на запросы через программный анализ) и Прогнозирование данных (разработка конвейера ML от начала до конца). В дополнение к интеграции существующих бенчмарков, таких как MLEBench и QRData, DSGym вводит оригинальные наборы данных, создавая два новых набора: DSBio и DSPredict. Эти наборы охватывают широкий спектр задач и могут эффективно тренировать модели, генерируя синтетические запросы.
Наши результаты показывают, что эти данные могут быть эффективным способом улучшения производительности моделей на задачах Data Science, даже для небольших моделей. Мы также провели анализ ошибок, чтобы понять, почему модели не справляются с задачами, и выявили интересные паттерны, которые помогут в дальнейшем развитии фреймворка.
Ускорьте внимание с FlashAttention-3: новые возможности и производительность
Together AI улучшает сервис дообучения с поддержкой инструментов
Похожие статьи

Усложнение управления ИТ для предприятий с ростом AI на краю сети
Gemma 4 от Google создает новые вызовы для безопасности ИТ в компаниях.
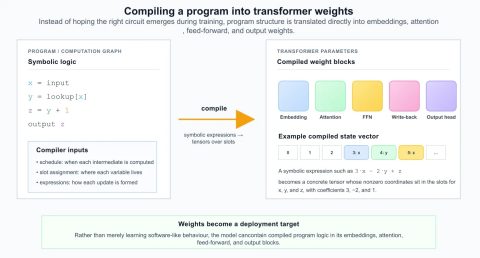
Создание мини-компьютера внутри трансформера для выполнения программ
Исследователи разработали мини-компьютер внутри трансформера для выполнения программ.

Агенты ReAct теряют 90% попыток — как это исправить
Исследование показало, что агенты ReAct теряют 90% попыток на ошибки, которые не могут быть исправлены.