Эффективные функции вознаграждения для настройки Amazon Nova с AWS Lambda

Создание эффективных функций вознаграждения помогает настраивать модели Amazon Nova в соответствии с конкретными потребностями, а AWS Lambda обеспечивает масштабируемую и экономически эффективную основу. Безсерверная архитектура Lambda позволяет сосредоточиться на определении качественных критериев, в то время как сама она управляет вычислительной инфраструктурой. Amazon Nova предлагает несколько подходов к настройке, среди которых выделяется обучение с подкреплением (RFT), позволяющее обучать модели желаемым поведением через итеративную обратную связь.
В отличие от обучения с учителем (SFT), требующего тысячи размеченных примеров с аннотированными путями рассуждений, RFT учится на оценочных сигналах конечных выводов. В центре RFT находится функция вознаграждения — механизм оценки, который направляет модель к более качественным ответам. Данная статья демонстрирует, как Lambda обеспечивает масштабируемые и экономически эффективные функции вознаграждения для настройки Amazon Nova. Вы научитесь выбирать между обучением с подкреплением с проверяемыми вознаграждениями (RLVR) для объективно проверяемых задач и обучением с подкреплением на основе обратной связи от ИИ (RLAIF) для субъективной оценки, а также разрабатывать многомерные системы вознаграждений, которые помогают предотвратить манипуляции с вознаграждением.
Оптимизация функций Lambda для масштабов обучения и мониторинг распределения вознаграждений с помощью Amazon CloudWatch также будут рассмотрены. Рабочие примеры кода и руководство по развертыванию помогут вам начать эксперименты. У вас есть несколько путей для настройки фундаментальных моделей, каждый из которых подходит для различных сценариев. SFT отлично подходит, когда у вас есть четкие примеры ввода-вывода и вы хотите обучить конкретным паттернам ответов — это особенно эффективно для задач, таких как классификация или распознавание именованных сущностей.
Однако некоторые проблемы настройки требуют другого подхода. Когда приложениям необходимо, чтобы модели одновременно учитывали несколько качественных измерений — например, ответы службы поддержки, которые должны быть точными, эмпатичными, краткими и соответствовать бренду — или когда создание тысяч аннотированных путей рассуждений оказывается непрактичным, методы на основе подкрепления предлагают лучшее решение. RFT решает эти сценарии, обучаясь на оценочных сигналах, а не требуя исчерпывающих размеченных демонстраций правильных процессов рассуждений. Функции вознаграждения на основе AWS Lambda упрощают этот процесс через обучение на основе обратной связи.
Вместо того чтобы показывать модели тысячи эффективных примеров, вы предоставляете подсказки и определяете логику оценки, которая оценивает ответы — затем модель учится улучшаться через итеративную обратную связь. Этот подход требует меньше размеченных примеров, обеспечивая при этом точный контроль над желаемыми поведениями. Многомерное оценивание захватывает нюансы качественных критериев, предотвращая использование моделями упрощенных путей, в то время как безсерверная архитектура Lambda управляет переменными нагрузками обучения без необходимости управления инфраструктурой.
Результатом становится настройка Nova, доступная для разработчиков без глубоких знаний в области машинного обучения, но достаточно гибкая для сложных производственных случаев. Архитектура RFT использует AWS Lambda в качестве безсерверного оценщика вознаграждений, который интегрируется с учебным процессом Amazon Nova, создавая цикл обратной связи, который направляет обучение модели. Процесс начинается, когда ваша учебная задача генерирует кандидатные ответы от модели Nova для каждой учебной подсказки. Эти ответы поступают в вашу функцию Lambda, которая оценивает их качество по таким параметрам, как правильность, безопасность, форматирование и краткость.
Функция затем возвращает скалярные числовые оценки — обычно в диапазоне от -1 до 1 как лучшая практика. Более высокие оценки направляют модель на укрепление тех поведений, которые их вызвали, в то время как более низкие оценки отводят от паттернов, приведших к плохим ответам. Этот цикл повторяется тысячи раз в ходе обучения, постепенно формируя модель к ответам, которые постоянно получают более высокие вознаграждения. Архитектура объединяет несколько сервисов AWS в единое решение по настройке. Lambda выполняет вашу логику оценки вознаграждений с автоматическим масштабированием, которое справляется с переменными требованиями к обучению без необходимости предоставления или управления инфраструктурой.
Amazon Bedrock предоставляет полностью управляемый опыт RFT с интегрированной поддержкой Lambda, предлагая модели AI-оценщиков для реализаций RLAIF через простой интерфейс программирования приложений (API). Для команд, нуждающихся в продвинутом контроле обучения, Amazon SageMaker AI предлагает варианты через Amazon SageMaker AI Training Jobs и Amazon SageMaker AI HyperPod, оба поддерживают те же функции вознаграждений на основе Lambda. Amazon CloudWatch в реальном времени мониторит производительность Lambda, регистрирует подробную отладочную информацию о распределении вознаграждений и прогрессе обучения, а также вызывает оповещения, когда возникают проблемы. В основе всего этого лежит сама Amazon Nova — модели с рецептами настройки, оптимизированные для широкого спектра случаев использования, которые эффективно реагируют на сигналы обратной связи, предоставляемые вашими функциями вознаграждений.
Этот безсерверный подход делает настройку Nova экономически эффективной. Lambda автоматически масштабируется от обработки 10 параллельных оценок в секунду во время начальных экспериментов до более 400 оценок во время производственного обучения, без настройки инфраструктуры или планирования емкости. Ваша одна функция Lambda может одновременно оценивать несколько качественных критериев, предоставляя нюансированную, многомерную обратную связь, которая предотвращает использование моделями упрощенных путей оценки. Архитектура поддерживает как объективную проверку через RLVR — выполнение кода против тестовых случаев или валидацию структурированных выходов, так и субъективную оценку через RLAIF, где модели ИИ оценивают такие качества, как тон и полезность. Вы платите только за фактическое время вычислений во время оценки с поминутной тарификацией, что делает эксперименты доступными, сохраняя при этом экономическую эффективность.
Разработка агентного ИИ для достижения измеримых результатов
Применение Claude Code для нетехнических задач на компьютере
Похожие статьи

Microsoft разрабатывает новый агент с функциями OpenClaw
Microsoft тестирует новый агент с функциями OpenClaw для бизнеса.
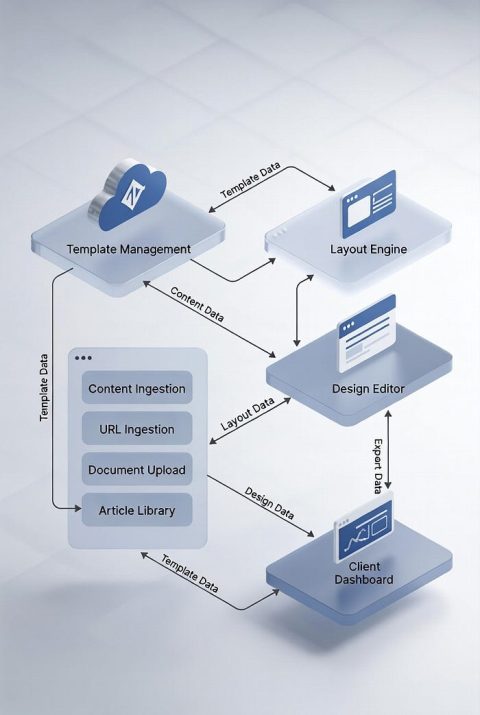
Sqribble и автоматизация документооборота на основе шаблонов
Sqribble представляет собой платформу для автоматизации документооборота с использованием шаблонов.
Разработка рабочего процесса с NVIDIA PhysicsNeMo для машинного обучения
Изучите, как реализовать NVIDIA PhysicsNeMo для машинного обучения на примере 2D Darcy Flow.