Effective reward functions for customizing Amazon Nova with AWS Lambda

Building effective reward functions helps customize Amazon Nova models to specific needs, with AWS Lambda providing a scalable and cost-effective foundation. Lambda's serverless architecture allows you to focus on defining quality criteria while it manages the computational infrastructure. Amazon Nova offers multiple customization approaches, with Reinforcement Fine-Tuning (RFT) standing out for its ability to teach models desired behaviors through iterative feedback.
Unlike Supervised Fine-Tuning (SFT), which requires thousands of labeled examples with annotated reasoning paths, RFT learns from evaluation signals on final outputs. At the heart of RFT lies the reward function—a scoring mechanism that guides the model toward better responses. This post demonstrates how Lambda enables scalable and cost-effective reward functions for Amazon Nova customization. You will learn to choose between Reinforcement Learning via Verifiable Rewards (RLVR) for objectively verifiable tasks and Reinforcement Learning via AI Feedback (RLAIF) for subjective evaluation, as well as design multi-dimensional reward systems that help prevent reward hacking.
Optimizing Lambda functions for training scale and monitoring reward distributions with Amazon CloudWatch will also be discussed. Working code examples and deployment guidance will help you start experimenting. You have multiple pathways to customize foundation models, each suited for different scenarios. SFT excels when you have clear input-output examples and want to teach specific response patterns—it's particularly effective for tasks like classification or named entity recognition.
However, some customization challenges require a different approach. When applications need models to balance multiple quality dimensions simultaneously—like customer service responses that must be accurate, empathetic, concise, and brand-aligned—or when creating thousands of annotated reasoning paths proves impractical, reinforcement-based methods offer a better alternative. RFT addresses these scenarios by learning from evaluation signals rather than requiring exhaustive labeled demonstrations of correct reasoning processes. AWS Lambda-based reward functions simplify this through feedback-based learning.
Instead of showing the model thousands of effective examples, you provide prompts and define evaluation logic that scores responses—then the model learns to improve through iterative feedback. This approach requires fewer labeled examples while giving you precise control over desired behaviors. Multi-dimensional scoring captures nuanced quality criteria that prevent models from exploiting shortcuts, while Lambda's serverless architecture handles variable training workloads without infrastructure management.
The result is Nova customization that’s accessible to developers without deep machine learning expertise, yet flexible enough for sophisticated production use cases. The RFT architecture uses AWS Lambda as a serverless reward evaluator that integrates with the Amazon Nova training pipeline, creating a feedback loop that guides model learning. The process begins when your training job generates candidate responses from the Nova model for each training prompt. These responses flow to your Lambda function, which evaluates their quality across dimensions like correctness, safety, formatting, and conciseness.
The function then returns scalar numerical scores—typically in the -1 to 1 range as a best practice. Higher scores guide the model to reinforce the behaviors that produced them, while lower scores guide it away from patterns that led to poor responses. This cycle repeats thousands of times throughout training, progressively shaping the model toward responses that consistently earn higher rewards. The architecture brings together several AWS services in a cohesive customization solution. Lambda executes your reward evaluation logic with automatic scaling that handles variable training demands without requiring you to provision or manage infrastructure.
Amazon Bedrock provides the fully managed RFT experience with integrated Lambda support, offering AI judge models for RLAIF implementations through a simple Application Programming Interface (API). For teams needing advanced training control, Amazon SageMaker AI offers options through Amazon SageMaker AI Training Jobs and Amazon SageMaker AI HyperPod, both supporting the same Lambda-based reward functions. Amazon CloudWatch monitors Lambda performance in real-time, logs detailed debugging information about reward distributions and training progress, and triggers alerts when issues arise. At the foundation sits Amazon Nova itself—models with customization recipes optimized across a wide variety of use cases that respond effectively to the feedback signals your reward functions provide.
This serverless approach makes Nova customization cost-effective. Lambda automatically scales from handling 10 concurrent evaluations per second during initial experimentation to over 400 evaluations during production training, without infrastructure tuning or capacity planning. Your single Lambda function can assess multiple quality criteria simultaneously, providing the nuanced, multi-dimensional feedback that prevents models from exploiting simplistic scoring shortcuts. The architecture supports both objective verification through RLVR—running code against test cases or validating structured outputs—and subjective judgment through RLAIF, where AI models evaluate qualities like tone and helpfulness. You pay only for actual compute time during evaluation with millisecond billing granularity, making experimentation affordable while maintaining economic efficiency.
Designing the agentic AI enterprise for measurable performance
Applying Claude Code to Non-technical Tasks on Your Computer
Related articles
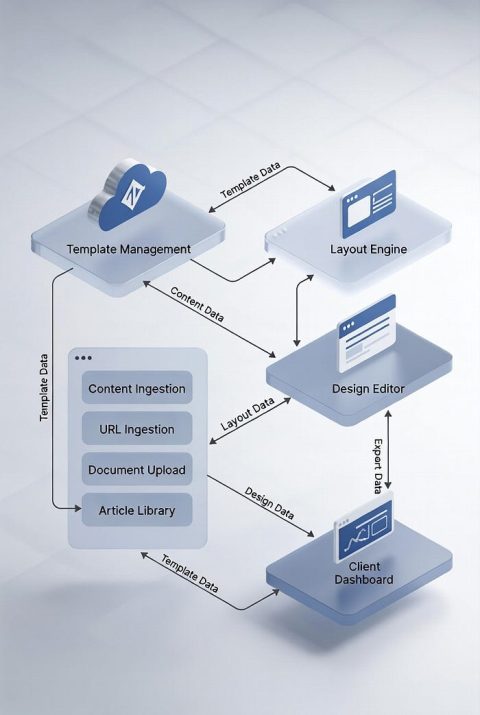
Sqribble and Template-Driven Document Automation
Sqribble serves as a platform for document automation using templates.
Developing a Workflow with NVIDIA PhysicsNeMo for Machine Learning
Learn how to implement NVIDIA PhysicsNeMo for machine learning using 2D Darcy Flow.
Anthropic Launches Managed Agents, Shaping the AI Agent Market
Anthropic launched Managed Agents, shaping the AI agent market and competing with Amazon and Google.