Hugging Face запускает TRL v1.0: унифицированный стек постобучения
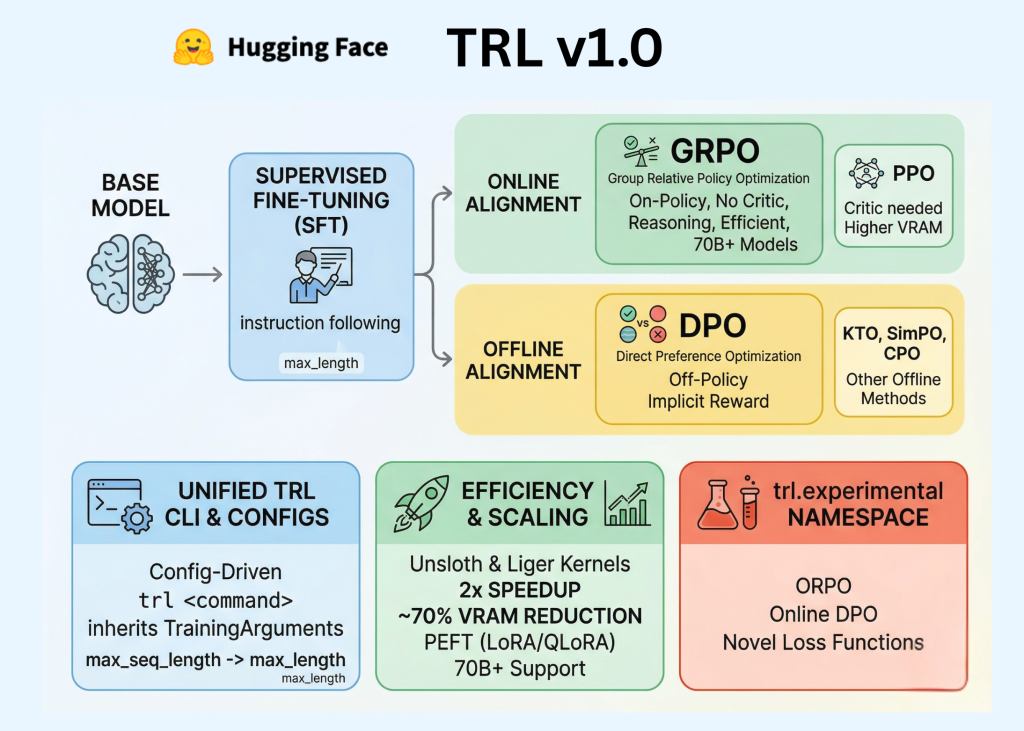
Компания Hugging Face официально представила TRL (Transformer Reinforcement Learning) v1.0, что знаменует собой важный переход библиотеки от исследовательского репозитория к стабильной, готовой к производству платформе. Для специалистов в области ИИ и разработчиков этот релиз закрепляет процесс постобучения — необходимую последовательность супервайзинга, моделирования вознаграждений и выравнивания — в едином, стандартизированном API.
На ранних этапах бумов языковых моделей постобучение часто рассматривалось как экспериментальное «темное искусство». TRL v1.0 стремится изменить это, предоставляя последовательный опыт разработки, основанный на трех основных принципах: специализированном интерфейсе командной строки (CLI), унифицированной системе конфигурации и расширенном наборе алгоритмов выравнивания, включая DPO, GRPO и KTO.
Постобучение — это этап, на котором предобученная базовая модель уточняется для выполнения инструкций, принятия определенного тона или демонстрации сложных способностей к рассуждению. TRL v1.0 организует этот процесс в отдельные, совместимые этапы: супервайзинг, моделирование вознаграждений и выравнивание.
Одним из самых значительных обновлений для программистов является внедрение надежного TRL CLI. Ранее инженеры должны были писать обширный шаблонный код и настраивать собственные циклы обучения для каждого эксперимента. TRL v1.0 вводит подход, основанный на конфигурации, который использует YAML-файлы или прямые аргументы командной строки для управления жизненным циклом обучения.
Кроме того, TRL v1.0 интегрирует несколько технологий, ориентированных на эффективность, чтобы адаптироваться к моделям с миллиардами параметров на потребительском или среднем корпоративном оборудовании. Поддержка PEFT (параметрически эффективного дообучения) позволяет обновлять лишь небольшую часть весов модели, значительно снижая требования к памяти. Интеграция с библиотекой Unsloth может удвоить скорость обучения и снизить использование памяти до 70% по сравнению со стандартными реализациями.
В заключение, TRL v1.0 стандартизирует постобучение языковых моделей с унифицированным CLI, системой конфигурации и рабочим процессом тренеров, что делает SFT, моделирование вознаграждений и выравнивание более воспроизводимыми для инженерных команд.
Обсуждаем GPT-5.4 и самоулучшающийся ИИ
Создайте и развивайте кастомного агента OpenAI с A-Evolve
Похожие статьи

Как модель в 10,000 раз меньше ChatGPT обходит его по умению
Модель в 10,000 раз меньше ChatGPT может обойти его, позволяя размышлять.
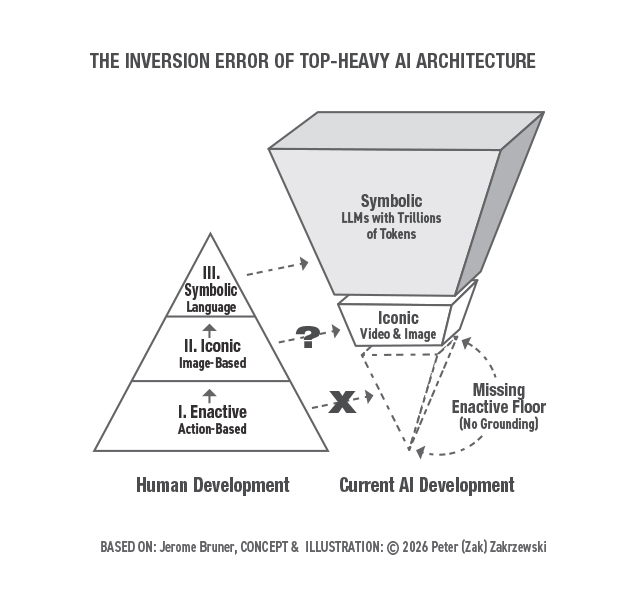
Понимание инверсной ошибки в безопасном AGI
Исследуем инверсную ошибку в AI и необходимость физического опыта для безопасного AGI.
Запускаем адаптивную систему спекулятивного обучения ATLAS
Together AI запускает ATLAS — адаптивную систему спекулятивного обучения для ускорения языковых моделей.