Современные методы RAG: кросс-кодеры и повторная сортировка
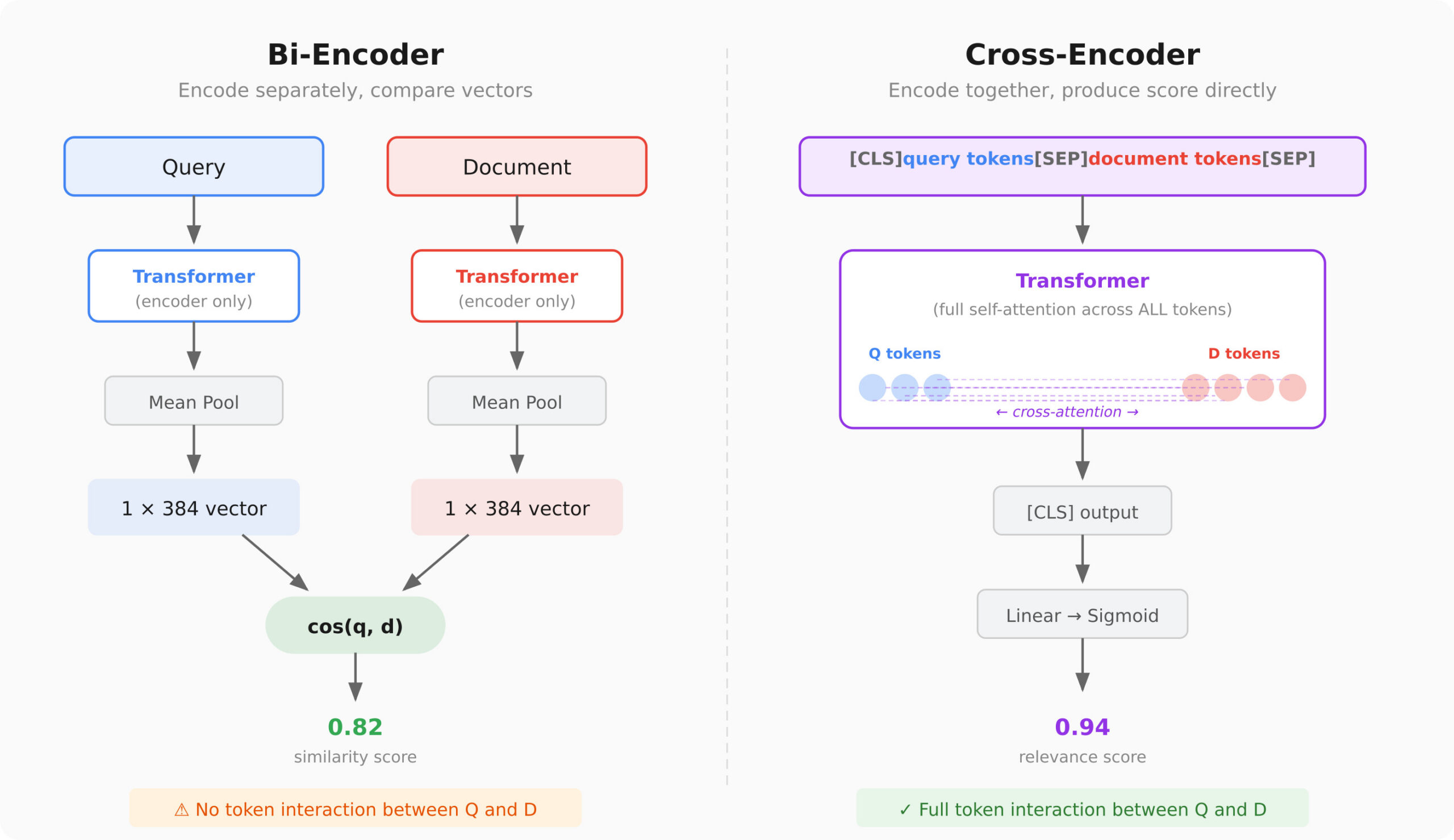
Семантический поиск, основанный на встраивании, стал ключевым компонентом во многих приложениях ИИ. Однако, многие из них до сих пор не используют повторную сортировку, несмотря на относительную простоту её реализации. Если вы когда-либо строили RAG-пipeline и думали, что результаты «приемлемы, но не отличные», решение не всегда заключается в выборе лучшей модели встраивания. Вместо этого стоит рассмотреть возможность добавления этапа повторной сортировки, и кросс-кодеры, вероятно, являются вашим лучшим выбором.
Кросс-кодеры «читают» запрос и документ вместе, что позволяет им учитывать противоречия, такие как «дешевые» и «$500/ночь». В отличие от би-кодеров, которые кодируют запрос и документ независимо, кросс-кодеры обеспечивают взаимодействие сигналов, что значительно улучшает качество сортировки.
В реальном мире можно использовать комбинацию би-кодеров и кросс-кодеров для достижения оптимальной производительности. На первом этапе происходит быстрая, приблизительная сортировка, а на втором — точная повторная сортировка с использованием кросс-кодеров. Это уже довольно стандартная практика в производстве, и многие компании предлагают API для повторной сортировки, такие как Cohere и Pinecone.
Несмотря на преимущества кросс-кодеров, есть и недостатки. Они требуют значительных вычислительных ресурсов, так как не могут предвычислить ничего. Это означает, что каждый запрос требует полного прохода через трансформер для каждого кандидата, что может занять много времени при большом количестве документов.
Таким образом, несмотря на то, что кросс-кодеры обеспечивают более точные результаты, их использование везде нецелесообразно из-за вычислительных затрат. Поэтому двухступенчатая система, которая сочетает в себе преимущества обоих подходов, является наиболее оптимальной для современных систем семантического поиска.
Почему каждому AI-ассистенту по программированию нужна память
Ученые MIT, NVIDIA и Университета Чжэцзян предложили TriAttention для оптимизации ИИ
Похожие статьи

Усложнение управления ИТ для предприятий с ростом AI на краю сети
Gemma 4 от Google создает новые вызовы для безопасности ИТ в компаниях.
Создание мини-компьютера внутри трансформера для выполнения программ
Исследователи разработали мини-компьютер внутри трансформера для выполнения программ.

Агенты ReAct теряют 90% попыток — как это исправить
Исследование показало, что агенты ReAct теряют 90% попыток на ошибки, которые не могут быть исправлены.