Advanced RAG Methods: Cross-Encoders and Reranking
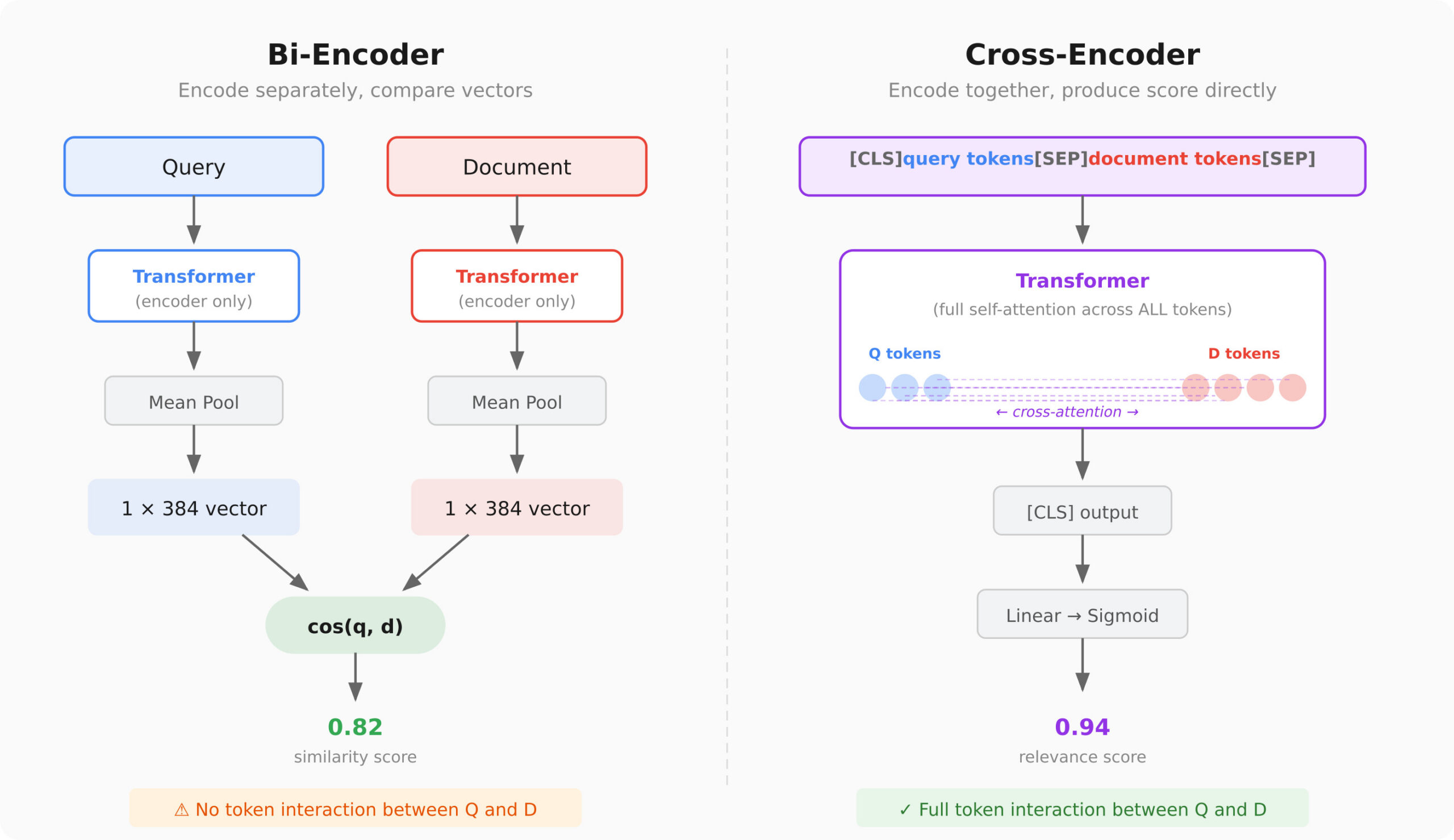
Semantic search, based on embeddings, has become a key component in many AI applications. However, many of them still do not utilize reranking, despite its relative ease of implementation. If you've ever built a RAG pipeline and thought the results were 'acceptable but not great,' the solution isn't always to choose a better embedding model. Instead, you should consider adding a reranking step, and cross-encoders are likely your best option.
Cross-encoders 'read' the query and document together, allowing them to capture contradictions such as 'cheap' and '$500/night.' Unlike bi-encoders, which encode the query and document independently, cross-encoders provide interaction signals that significantly enhance sorting quality.
In the real world, a combination of bi-encoders and cross-encoders can be used to achieve optimal performance. The first stage involves fast, approximate retrieval, while the second stage employs precise reranking using cross-encoders. This approach is already quite standard in production, with many companies offering reranking APIs, such as Cohere and Pinecone.
Despite the advantages of cross-encoders, there are drawbacks. They require significant computational resources as they cannot precompute anything. This means that each query necessitates a full transformer pass for every candidate, which can be time-consuming with a large number of documents.
Thus, while cross-encoders provide more accurate results, using them exclusively is impractical due to computational costs. Therefore, a two-stage system that combines the benefits of both approaches is the most optimal for modern semantic search systems.
Why Every AI Coding Assistant Needs a Memory Layer
Researchers from MIT, NVIDIA, and Zhejiang University Introduce TriAttention for AI Optimization
Related articles

Microsoft develops new agent with OpenClaw-like features
Microsoft is testing a new agent with OpenClaw-like features for enterprise.
Sqribble and Template-Driven Document Automation
Sqribble serves as a platform for document automation using templates.
Developing a Workflow with NVIDIA PhysicsNeMo for Machine Learning
Learn how to implement NVIDIA PhysicsNeMo for machine learning using 2D Darcy Flow.