Улучшите API пакетного вывода: новый интерфейс и поддержка моделей

Мы внедрили значительные улучшения в наш API пакетного вывода, делая его более простым, быстрым и мощным для команд, обрабатывающих огромные объемы данных. Теперь создание и отслеживание пакетных заданий возможно через интуитивно понятный интерфейс — без сложных вызовов API.
API пакетного вывода теперь поддерживает все серверные модели и частные развертывания, что позволяет запускать пакетные рабочие нагрузки на тех моделях, которые вам нужны. Лимиты по количеству токенов увеличены с 10 миллионов до 30 миллиардов на модель на пользователя, что составляет увеличение в 3000 раз. Если вам нужно больше, мы поможем вам настроить параметры.
Для большинства серверных моделей API пакетного вывода работает в два раза дешевле, чем наш API в реальном времени, что делает его наиболее экономичным способом обработки высокопроизводительных рабочих нагрузок. Мы полагаемся на API пакетного вывода для обработки очень больших объемов запросов. Высокие лимиты — до 30 миллиардов токенов — позволяют нам проводить масштабные эксперименты без узких мест, и задания завершаются значительно быстрее 24-часового SLA, зачастую всего за несколько часов.
API пакетного вывода идеально подходит, когда вам нужна высокая пропускная способность без ограничений в реальном времени. Он подходит для анализа текстов, обнаружения мошенничества, генерации синтетических данных, создания векторных представлений и автоматизации поддержки клиентов. Эти обновления знаменуют собой значительный шаг вперед в доступности и экономичности крупномасштабного вывода. С обновленным интерфейсом, универсальной поддержкой моделей и значительно более высокими лимитами — при этом обычно за половину стоимости API в реальном времени — API пакетного вывода является наиболее эффективным способом обработки больших рабочих нагрузок.
Попробуйте API пакетного вывода уже сегодня и начните масштабировать свои эксперименты без ограничений.
Анонсы исследований и продуктов на AI Native Conf
Улучшения платформы Fine-Tuning: большие модели и новые возможности
Похожие статьи

Агенты ReAct теряют 90% попыток — как это исправить
Исследование показало, что агенты ReAct теряют 90% попыток на ошибки, которые не могут быть исправлены.
Ученые MIT, NVIDIA и Университета Чжэцзян предложили TriAttention для оптимизации ИИ
Ученые предложили TriAttention для оптимизации KV-кэша в языковых моделях.
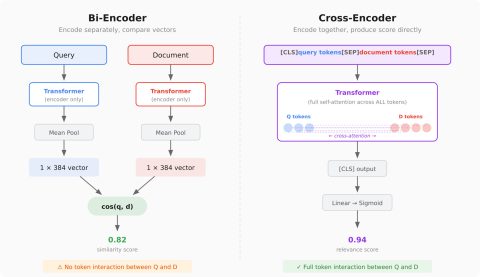
Современные методы RAG: кросс-кодеры и повторная сортировка
Изучите современные методы RAG, включая кросс-кодеры и повторную сортировку для улучшения качества поиска.