Hugging Face Launches TRL v1.0: A Unified Post-Training Stack
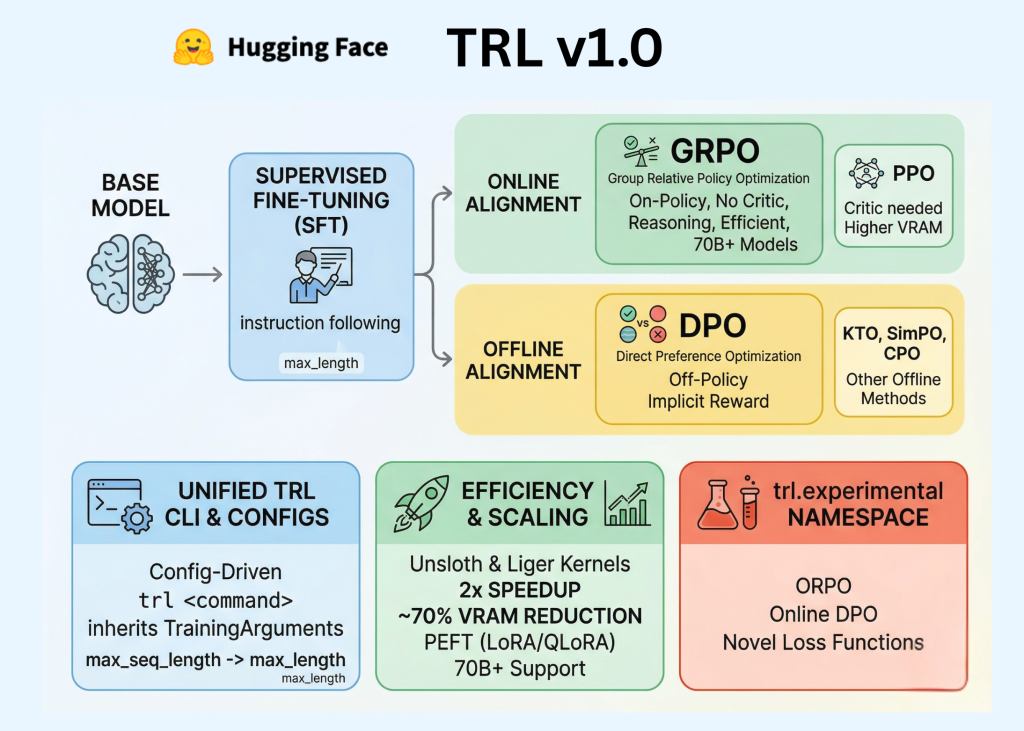
Hugging Face has officially released TRL (Transformer Reinforcement Learning) v1.0, marking a pivotal transition for the library from a research-oriented repository to a stable, production-ready framework. For AI professionals and developers, this release codifies the post-training pipeline—the essential sequence of Supervised Fine-Tuning (SFT), Reward Modeling, and Alignment—into a unified, standardized API.
In the early stages of the LLM boom, post-training was often treated as an experimental ‘dark art.’ TRL v1.0 aims to change that by providing a consistent developer experience built on three core pillars: a dedicated Command Line Interface (CLI), a unified Configuration system, and an expanded suite of alignment algorithms including DPO, GRPO, and KTO.
Post-training is the phase where a pre-trained base model is refined to follow instructions, adopt a specific tone, or exhibit complex reasoning capabilities. TRL v1.0 organizes this process into distinct, interoperable stages: Supervised Fine-Tuning (SFT), Reward Modeling, and Alignment.
One of the most significant updates for software engineers is the introduction of a robust TRL CLI. Previously, engineers were required to write extensive boilerplate code and custom training loops for every experiment. TRL v1.0 introduces a config-driven approach that utilizes YAML files or direct command-line arguments to manage the training lifecycle.
Additionally, TRL v1.0 integrates several efficiency-focused technologies to accommodate models with billions of parameters on consumer or mid-tier enterprise hardware. Native support for PEFT (Parameter-Efficient Fine-Tuning) allows fine-tuning by updating a small fraction of the model’s weights, drastically reducing memory requirements. Integration with the Unsloth library can result in a 2x increase in training speed and up to a 70% reduction in memory usage compared to standard implementations.
In conclusion, TRL v1.0 standardizes LLM post-training with a unified CLI, configuration system, and trainer workflow, making SFT, reward modeling, and alignment more reproducible for engineering teams.
Discussing GPT-5.4 and Self-Improving AI
Build and Evolve a Custom OpenAI Agent with A-Evolve
Похожие статьи
Announcing Replicate's remote MCP server for applications
Replicate announced a remote MCP server for applications, simplifying access to APIs.
Use Veo 3 to Animate Images Effectively
Use Veo 3 to animate images while preserving their style and adding dynamics.
Launch Open Source Video with Wan 2.2 and Pruna AI
Wan 2.2 brings back open source video with new features and low prices.