Document Extraction System for 4,700 PDFs in 45 Minutes
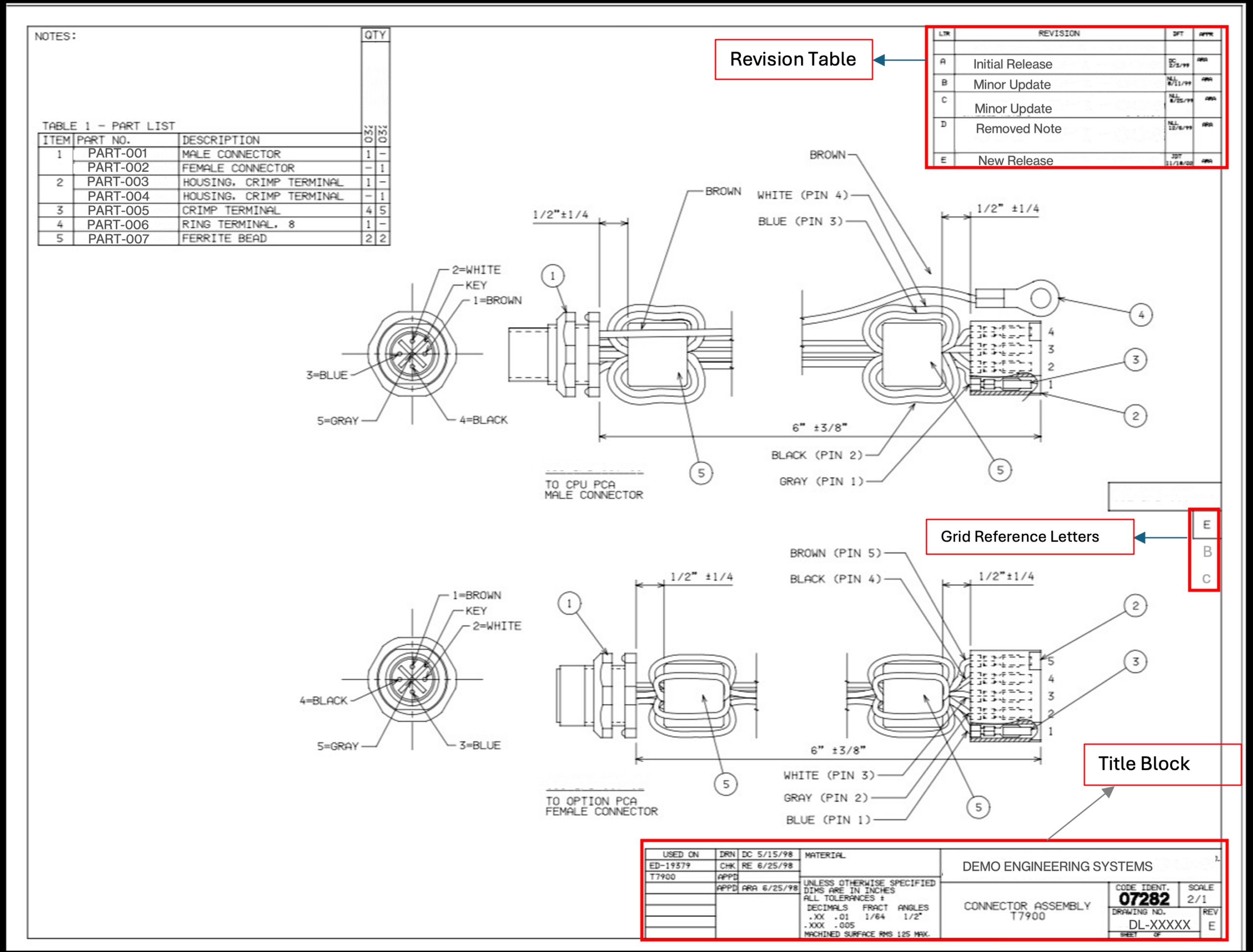
Recently, I was asked to assist in extracting revision numbers from over 4,700 engineering drawing PDFs. This was necessary for migrating to a new asset management system, where current REV values needed to be retrieved from document title blocks. Otherwise, a team of engineers would have to manually open each PDF, which would take about four weeks of work and cost over £8,000. However, this was not an AI problem; it was a systems design challenge with real constraints: budget, accuracy requirements, and mixed file formats.
Engineering drawings are not ordinary PDFs. Some were created in CAD software and exported as text-based PDFs, allowing for programmatic text extraction. Others, especially older drawings, were scanned and saved as images, complicating the task. Over 70% of the documents were text-based, but even among them, various REV formats and potential false positives posed challenges.
While it would have been possible to use GPT-4 Vision for data extraction, that approach would have been impractical due to high costs and processing time. Instead, we opted for a hybrid approach, where the first stage employed PyMuPDF for text extraction, and the second stage utilized GPT-4 Vision for documents where the first method failed.
In the first stage, we attempted to extract text from the bottom right quadrant of the page, where title blocks typically reside. By using specific keywords, we significantly reduced false positive rates. If no result was obtained in the first stage, we moved to the second stage, processing PDF images with GPT-4 Vision.
During implementation, we encountered issues related to orientation ambiguity. Engineering drawings are often stored in landscape orientation, and PDF metadata does not always accurately reflect this. We conducted numerous tests to determine the optimal resolution for image processing without sacrificing quality.
Google Maps introduces AI for generating photo captions
Uber expands contract with Amazon to use AI chips
Related articles

Meta Researchers Introduce Hyperagents for Self-Improving AI
Meta researchers have introduced hyperagents that enhance AI for non-coding tasks.

OpenAI updates its Agents SDK to help enterprises build safer solutions
OpenAI has updated its Agents SDK, adding new features for businesses.
Optimizing GPU Usage for Language Models and Reducing Costs
Optimizing GPU usage for language models reduces costs and increases efficiency.