Система извлечения данных из 4,700 PDF за 45 минут
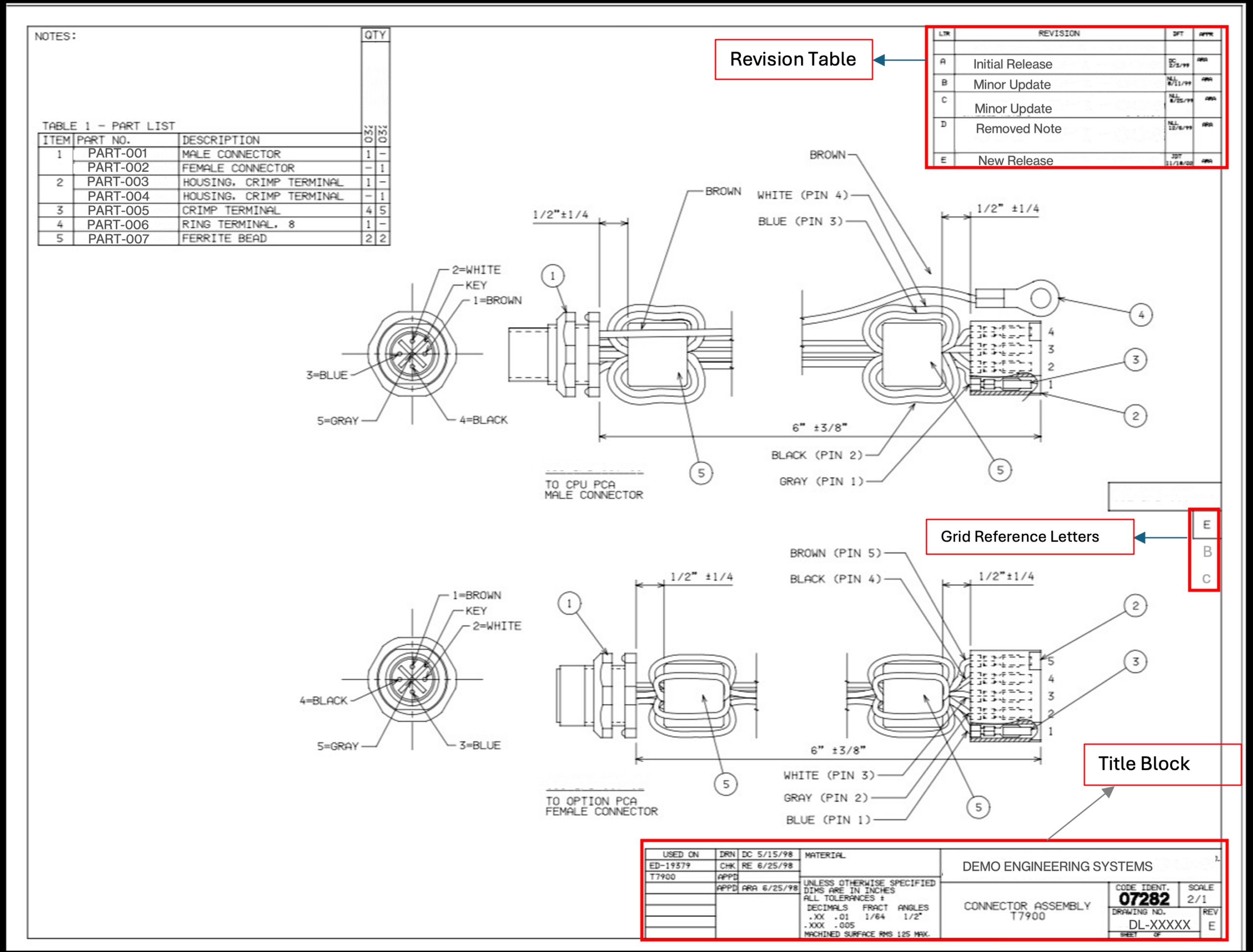
Недавно мне предложили помочь извлечь номера ревизий из более чем 4,700 PDF-документов с инженерными чертежами. Это было необходимо для перехода на новую систему управления активами, где требовалось получить актуальные значения REV из заголовков документов. В противном случае команде инженеров пришлось бы вручную открывать каждый PDF, что заняло бы около четырех недель работы и стоило бы более £8,000. Однако это не была проблема, связанная с ИИ, а задача по проектированию системы с реальными ограничениями: бюджет, требования к точности и смешанные форматы файлов.
Инженерные чертежи представляют собой не обычные PDF-документы. Некоторые из них были созданы в CAD-программах и экспортированы в текстовые PDF, из которых можно программно извлекать текст. Другие, особенно старые чертежи, были отсканированы и сохранены как изображения, что усложняло задачу. Более 70% документов были текстовыми, но даже среди них возникали трудности с различными форматами значений REV и возможными ложными срабатываниями.
Хотя можно было бы использовать GPT-4 Vision для извлечения данных, это было бы нецелесообразно из-за высоких затрат и времени обработки. Вместо этого мы решили применить гибридный подход, где первая стадия использовала PyMuPDF для извлечения текста, а вторая стадия — GPT-4 Vision для обработки тех документов, где первый метод не сработал.
На первой стадии мы пытались извлечь текст из нижнего правого квадрата страницы, где обычно находятся заголовки. Используя определенные ключевые слова, мы смогли значительно сократить количество ложных срабатываний. Если на первой стадии результат не был получен, мы переходили ко второй стадии, где обрабатывали изображения PDF-документов с помощью GPT-4 Vision.
В процессе реализации мы столкнулись с проблемами, связанными с неоднозначностью ориентации документов. Инженерные чертежи часто сохранялись в альбомной ориентации, и метаданные PDF не всегда корректно отражали это. Мы провели множество тестов, чтобы определить оптимальное разрешение для обработки изображений без потери качества.
Google Maps внедряет ИИ для создания подписей к фотографиям
Uber расширяет контракт с Amazon для использования AI-чипов
Похожие статьи

Исследователи Meta представили гиперагенты для самообучающегося ИИ
Исследователи Meta представили гиперагенты, которые улучшают ИИ для не программируемых задач.

OpenAI обновляет SDK для агентов, чтобы помочь компаниям создавать более безопасные решения
OpenAI обновила SDK для агентов, добавив новые функции для бизнеса.
Оптимизация использования GPU для языковых моделей и снижение затрат
Оптимизация GPU для языковых моделей снижает затраты и повышает эффективность.