Снижение затрат на контрольные точки при помощи Python и NVIDIA nvCOMP

Обучение языковых моделей требует периодического создания контрольных точек. Эти полные снимки весов модели, состояний оптимизаторов и градиентов сохраняются на носителе, чтобы обучение могло возобновиться после прерываний. На больших масштабах контрольные точки становятся огромными (782 ГБ для модели на 70 миллиардов параметров) и частыми (каждые 15-30 минут), что создает одну из самых крупных статей расходов в бюджете на обучение. Большинство команд по искусственному интеллекту сосредоточены на использовании GPU, пропускной способности обучения и качестве модели. Почти никто не обращает внимания на затраты на контрольные точки, что является дорогостоящей ошибкой.
Синхронные накладные расходы на контрольные точки для модели на 405 миллиардов параметров на 128 GPU NVIDIA DGX B200 могут стоить 200 000 долларов в месяц. Внедрение шага без потерь для сжатия, реализованного всего на 30 строках Python, может снизить затраты на хранение на 56 000 долларов в месяц. Модели с миксом экспертов (MoE) позволяют сэкономить еще больше. В этом посте мы разберем, как мы пришли к таким расчетам и как NVIDIA nvComp может улучшить эффективность создания контрольных точек.
На практике аппаратные прерывания при использовании более 1000 GPU не редкость. Meta сообщила о 419 неожиданностях за 54 дня обучения Llama 3 на 16 384 GPU NVIDIA H100. Именно поэтому большинство команд создают контрольные точки каждые 15-30 минут; это не опциональная накладная статья, а необходимая инфраструктура. Стандартная практика заключается в создании 48 контрольных точек в день, что за месяц непрерывного обучения составляет 1,13 ПБ, записанных на носитель.
Кроме того, во время каждой синхронной записи контрольной точки все 8 GPU остаются полностью бездействующими. Время ожидания для каждой записи контрольной точки составляет около 156,4 секунд, что приводит к затратам на бездействующие GPU более 2200 долларов в месяц, не учитывая платы за хранение. При увеличении до 64 GPU эти затраты превышают 17 500 долларов в месяц, а при 128 GPU они превышают 200 000 долларов.
Асинхронное создание контрольных точек частично решает проблему, однако поддержка фреймворков все еще находится в стадии развития. Альтернативная техника, которую можно легко использовать, — это сжатие контрольных точек, которое также сокращает время холодного старта при восстановлении состояния. NVIDIA nvCOMP предлагает ускоренное сжатие с использованием GPU, что позволяет выполнять сжатие прямо в памяти GPU без дополнительных затрат на передачу данных.
Мы настроили две архитектуры моделей и сжали каждую компоненту с использованием nvCOMP на GPU NVIDIA H200 и B200. Соотношение сжатия зависит от данных, а не от оборудования. ZSTD и ANS — это алгоритмы, которые обеспечивают высокую скорость сжатия и могут быть легко интегрированы в рабочие процессы Python. Выбор между ними зависит от скорости вашего хранилища.
Новый AI-инструмент оптимизирует дизайн роботов-трансформеров
Понимание жизненного цикла моделей Amazon Bedrock
Похожие статьи

Агенты ReAct теряют 90% попыток — как это исправить
Исследование показало, что агенты ReAct теряют 90% попыток на ошибки, которые не могут быть исправлены.
Ученые MIT, NVIDIA и Университета Чжэцзян предложили TriAttention для оптимизации ИИ
Ученые предложили TriAttention для оптимизации KV-кэша в языковых моделях.
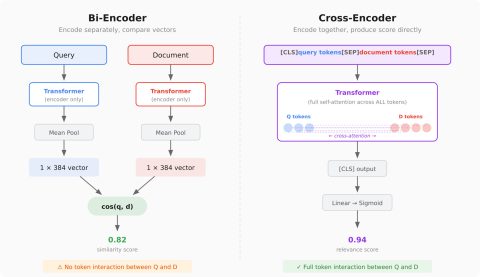
Современные методы RAG: кросс-кодеры и повторная сортировка
Изучите современные методы RAG, включая кросс-кодеры и повторную сортировку для улучшения качества поиска.