Создайте AI-сеть с NVIDIA: Оркеструйте интеллект повсюду

Сервисы, ориентированные на ИИ, выявляют новую узкую горлышко в инфраструктуре ИИ: с ростом числа пользователей, агентов и устройств, требующих доступ к интеллекту, задача смещается от пиковой пропускной способности обучения к обеспечению детерминированного вывода в масштабе. На GTC 2026 NVIDIA объявила, что телекоммуникационные компании и распределенные облачные провайдеры преобразуют свои сети в AI-сети, внедряя ускоренные вычисления по всей сети региональных узлов, центральных офисов и периферийных местоположений для удовлетворения потребностей сервисов на основе ИИ.
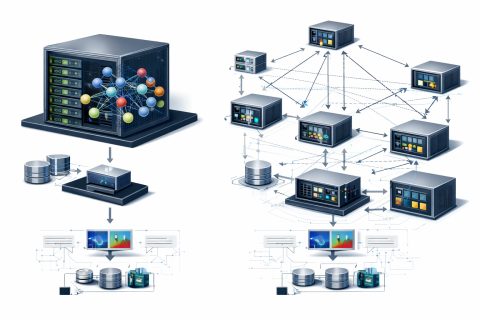
AI-сети делают возможными реализацию многомодальных и гиперперсонализированных ИИ-опытов в реальном времени за счет выполнения вывода на распределенной, осведомленной о нагрузках, ресурсах и ключевых показателях эффективности (KPI) инфраструктуре ИИ. Справочная модель AI Grid от NVIDIA предоставляет единый фреймворк для создания географически распределенной, взаимосвязанной и оркестрированной инфраструктуры ИИ. Ключевым аспектом этого дизайна является управляющая плоскость AI-сети, которая превращает изолированные кластеры и регионы в единую программируемую платформу.
Умное размещение рабочих нагрузок имеет критическое значение для приложений, где задержка, пропускная способность, персонализация или суверенитет становятся первоочередными ограничениями проектирования. Например, для приложений с высокими требованиями к задержке, таких как физические ИИ (роботы, датчики), разговорные агенты и дополненная реальность, необходимо оптимизировать задержку и колебания. AI-сети не только ускоряют классические приложения на краю, но и открывают новый набор сервисов, основанных на ИИ, построенных вокруг генерации и персонализации в реальном времени.
Одним из примеров является использование AI-сетей для голосовых сервисов, где критически важна задержка. Услуги голосового ИИ чувствительны к задержке, и превышение 500 мс делает разговоры заметно запаздывающими для пользователей. Поэтому достижение этого времени первого токена на клиенте становится жестким целевым показателем. Важно, чтобы AI-сети обеспечивали значительные улучшения задержки, размещая вывод на региональных узлах, что сокращает время кругового путешествия и уменьшает задержку в очереди.
Бенчмарк от Comcast показывает, что развертывание AI-сети поддерживает задержку голосовых взаимодействий в пределах 500 мс, даже при пиковых нагрузках. Это достигается за счет размещения вывода на региональных узлах, что сокращает время кругового путешествия и уменьшает задержку в очереди. Кроме того, производительность при увеличении нагрузки также улучшается, так как четыре узла на краю поглощают спрос параллельно, достигая 42,362 токенов в секунду при пиковых нагрузках, что на 80.9% больше, чем в базовом режиме.
Разворачиваем раздельные нагрузки LLM на Kubernetes
Автоматизация больниц с помощью робототехники и симуляции
Похожие статьи

Исследователи Meta представили гиперагенты для самообучающегося ИИ
Исследователи Meta представили гиперагенты, которые улучшают ИИ для не программируемых задач.

OpenAI обновляет SDK для агентов, чтобы помочь компаниям создавать более безопасные решения
OpenAI обновила SDK для агентов, добавив новые функции для бизнеса.
Оптимизация использования GPU для языковых моделей и снижение затрат
Оптимизация GPU для языковых моделей снижает затраты и повышает эффективность.