Building a text-to-SQL solution using Amazon Bedrock

Building a text-to-SQL solution using Amazon Bedrock can alleviate one of the most persistent bottlenecks in data-driven organizations: the delay between asking a business question and getting a clear, data-backed answer. You might be familiar with the challenge of navigating competing priorities when your one-time question is waiting in the queue behind higher-impact work. A text-to-SQL solution augments your existing team—business users self-serve routine analytical questions, freeing up technical capacity across the organization for complex, high-value initiatives.
Questions like “What is our year-over-year revenue growth by customer segment?” become accessible to anyone, without creating an additional workload for technical teams. Many organizations find that accessing data insights remains a significant bottleneck in business decision-making processes. The traditional approach requires either learning SQL syntax, waiting for technical resources, or settling for pre-built dashboards that might not answer your specific questions.
In this post, we show you how to build a natural text-to-SQL solution using Amazon Bedrock that transforms business questions into database queries and returns actionable answers. The model returns not only raw SQL, but executed results synthesized into clear, natural language narratives in seconds rather than hours. We walk you through the architecture, implementation strategies, and lessons learned from deploying this solution at scale.
It’s worth noting that tools like Amazon Quick already address many self-service analytics needs effectively, including natural language querying of dashboards and automated insight generation. These tools are an excellent fit when your analytics requirements align with structured dashboards, curated datasets, and governed reporting workflows.
A custom text-to-SQL solution becomes valuable when users must query across complex, multi-table schemas with deep organizational business logic, domain-specific terminology, and one-time questions beyond what pre-configured dashboard datasets support.
Open Solutions in Marketing Mix Models Using GenAI
Intel joins Elon Musk's Terafab chips project
Related articles
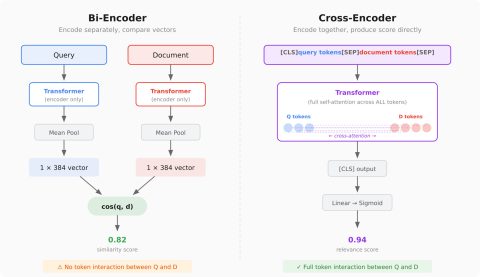
Advanced RAG Methods: Cross-Encoders and Reranking
Explore advanced RAG methods, including cross-encoders and reranking to enhance search quality.

How Knowledge Distillation Compresses Ensemble Intelligence into a Single Deployable AI Model
Knowledge distillation allows creating compact AI models inheriting ensemble performance.

NVIDIA introduces AITune: a toolkit for optimizing PyTorch model inference
NVIDIA has introduced AITune, a tool for automating the optimization of PyTorch models.